

Shooty Fruity | Mixed Reality Trailer

Phantom: Covert Ops | Trailer
Teaser trailer

Dove Men + Care | Campaign
Ad Campaign
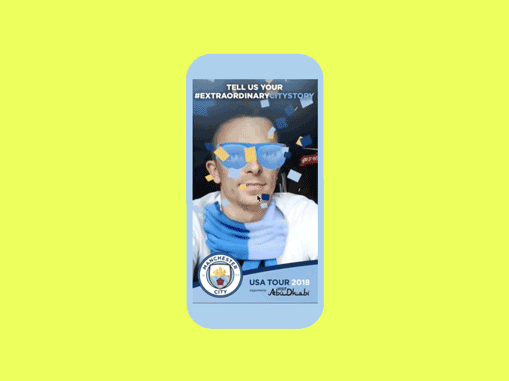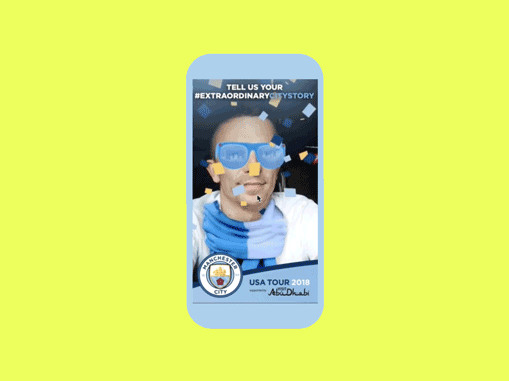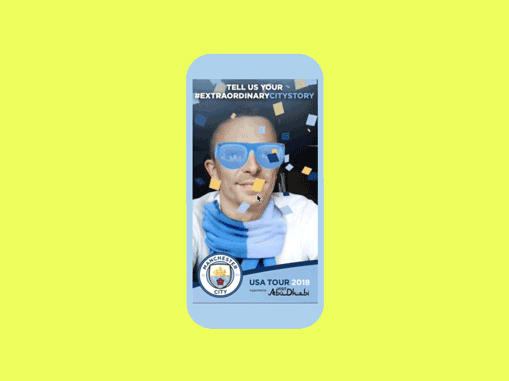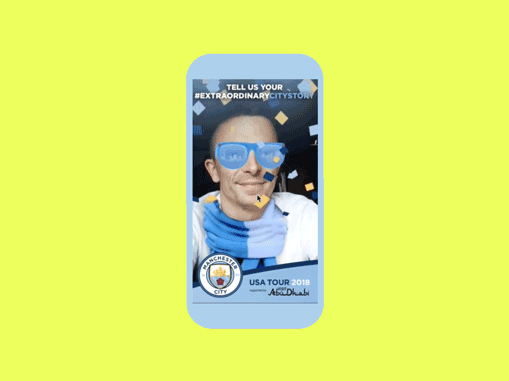
MCFC USA Tour | AR Campaign
AR Campaign

Hitman 2 | Launch Campaign
Digital Launch Campaign

Beauty & the Bear | Branding
Branding

Perfect Balloon Flight | Keyart
Keyart

Hitman: Sniper Assassin | Campaign
Branding & Campaign Strategy

No Man's Sky | Digital Campaign
Digital Campaign
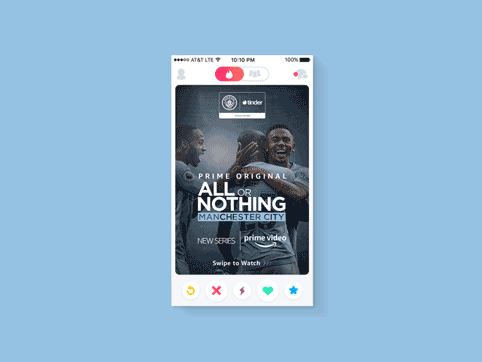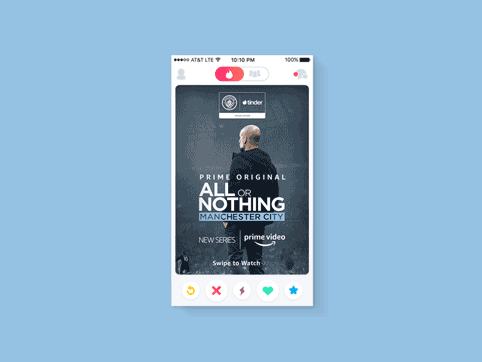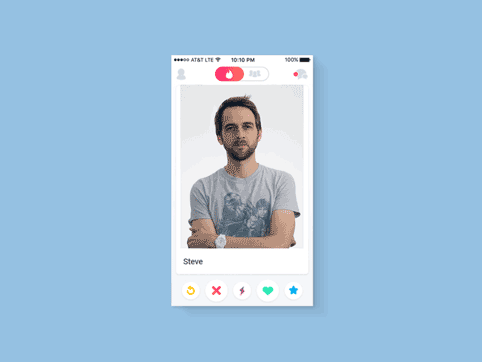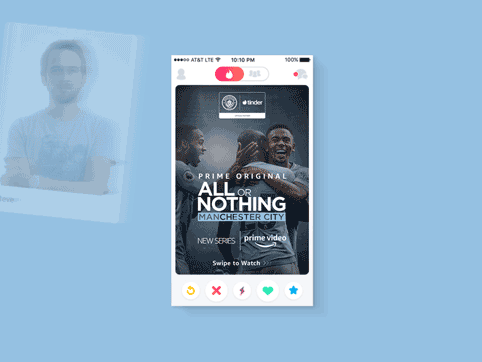
MCFC All Or Nothing | Digital ads
Digital Campaign

Sonic Dash | Artwork + Campaign
Digital creative

Shooty Fruity | Branding
Branding

Dermatica | Social rebrand
Branding

Bloody Zombies | Keyart Branding
Keyart & Branding

Bloody Zombies | Switch Trailer

Avantia | Branding
Branding

Sonic Lost World | Creative
Launch Campaign & Packaging

Perfect | Keyart & Branding
Keyart

Cobain Montage of Heck | Poster
Universal | Gifting Campiagn

Copy of Documentary

Copy of Screenshots

Copy of Photography

Lionsgate
My first Job!